,有助於車隊管理員管理駕駛行為、運動感測、急煞車和衝擊偵測.jpg?timestamp=1689918406.42007)





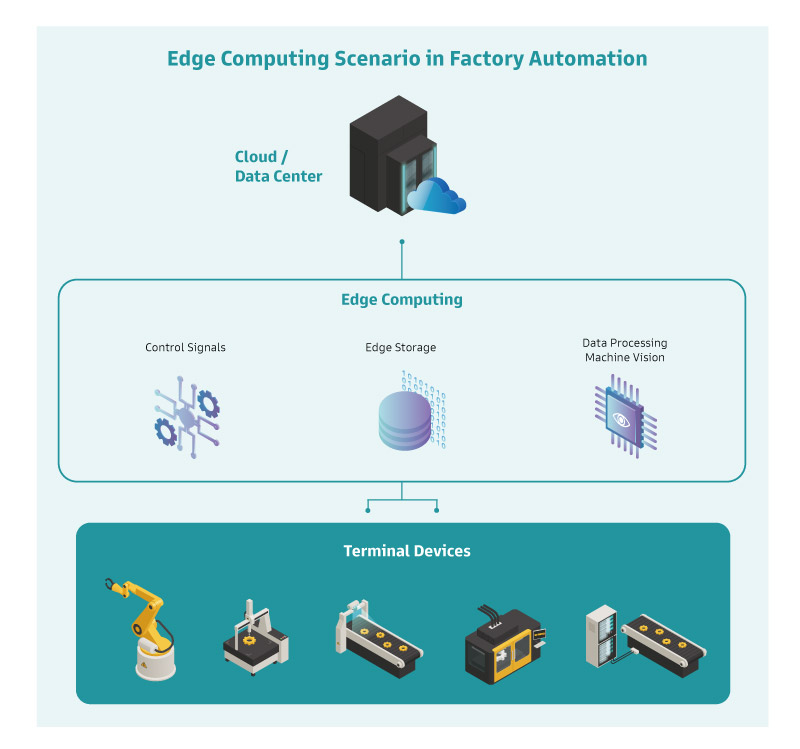
With the growing demand for performance in edge computing, the ability to efficiently carry and process large amounts of data at the terminal has become a significant bottleneck for industrial plants and medical applications. With space at a premium, installing high-performance edge servers is the most effective way to reduce operational and maintenance costs by minimizing floor space and simplifying deployment architecture. DFI's ICX610-C621A ATX motherboard with Intel Xeon processors provides reliable performance for AI applications and abundant expansion slots to provide ample bandwidth. Simplifying the deployment of edge computing devices and increasing productivity with the most streamlined architecture.
Industry: Edge Computing / Edge Server
Application: Industrial Automation and Medical Imaging System
Solution: ICX610-C621A ATX Motherboard