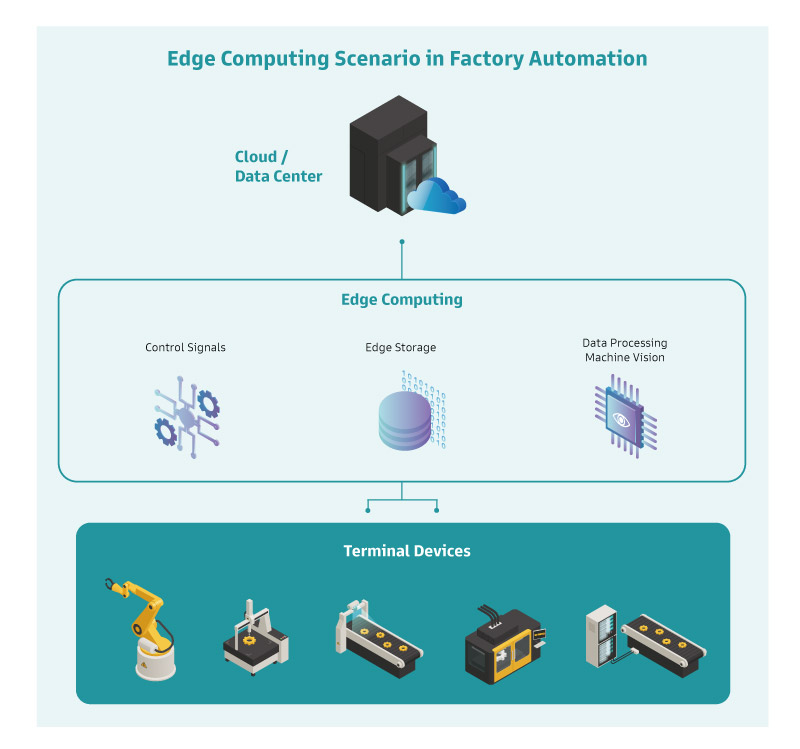
邊緣運算伺服器 - 「效能」為決勝點
邊緣運算伺服器需具備微型資料中心及邊緣雲的能耐,不脫處理速度、傳輸速度與儲存效率。運算著重即時與精準,傳輸必須低延遲,而在資料的存取上得有足夠的頻寬與空間,這些都剛好是伺服器等級主機板的特長。
以 DFI ICX610-C621A-C621A 為例, 結合多核心多執行緒的第三代 Intel® Xeon® 處理器為多工好手,能滿足來自多台終端設備的資料處理需求,數量驚人的內外部傳輸埠口也提供了充裕的傳輸通道,同時可管理為數眾多的儲存裝置,這些邊緣伺服器的功能在此張主機板上全都能一次達成。
ICX610-C621A-C621A 專為 Intel® Ice Lake 平台量身打造, 支援第三代 Intel® Xeon® 處理器。此代 Xeon® 處理器於 AI 的運算能力極為突出,包含以下三方面的提升:
- Intel® Deep Learning Boost
- Intel® AVX-512
- 支援PCIe 4.0
Intel® Deep Learning Boost 搭配 Intel® AVX-512
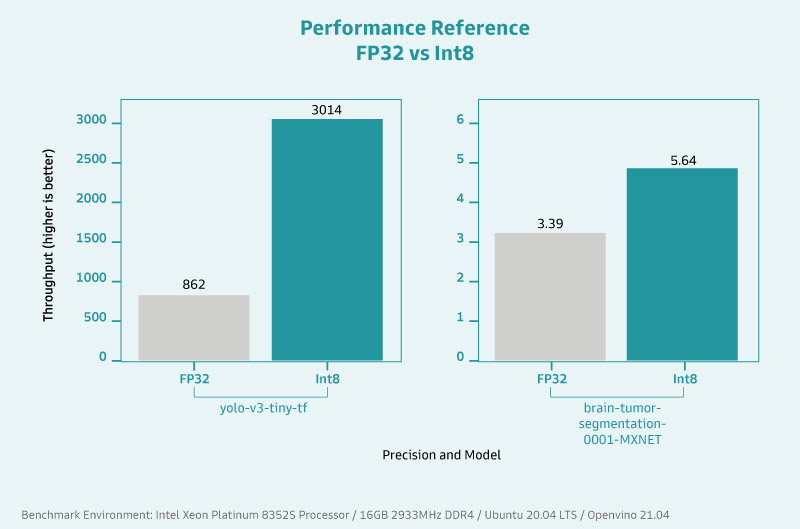
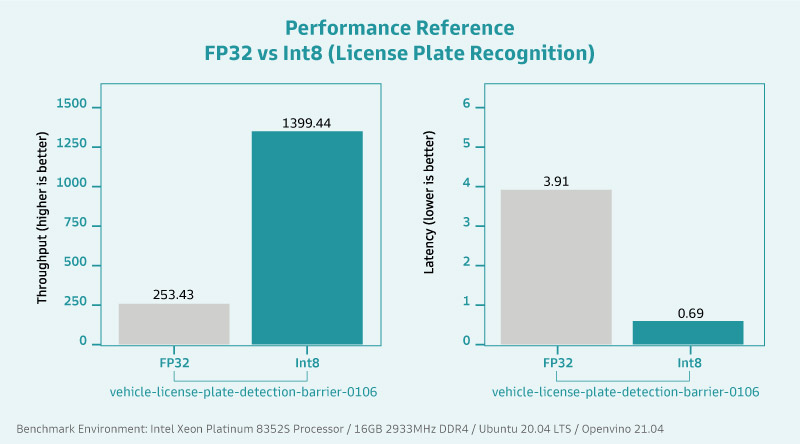
Intel®Deep Learning Boost 並非於此代 Xeon® 處理器才問世,但這個立基於 Intel® AVX512 VNNI 指令集的技術隨著處理器的更新而益發強勁,在深度學習及視覺分析效能方面都有顯著提升。在 AI 應用的訓練階段,效能便獲得60% 的提升,而在實際進行推論時,也比第一代快 30 倍以上。
用更嚴謹的數據來判斷及解析,VNNI 暴增了低精度運算在 AI 深度學習及推論的效能成長。透過低精度運算的優化,在進行 AI 應用時處理器的資料吞吐量大幅增加,平均可創造約 2.19 倍的差距,這意味著在時間上快了約 45%。
45% 的速度提升代表什麼?試想在產線上原本辨識一處產品缺陷的耗時為 25 毫秒(註 1),節省了近一半的時間後會小於 15 毫秒,積沙成塔下,同樣的時間內能辨識的產品數量就會變多,大量佈署下能節省的工時及產力提升更是不言而諭。
而在醫療應用上,辨識速度的提升對於受檢者而言,亦可大幅降低容易造成不適的生理掃描或幅射曝露時間,提供更優質的檢測體驗。
*( 註1) 辨識速度依圖像複雜度及機器負載而異,此處數值純粹做為對比用。







,有助於車隊管理員管理駕駛行為、運動感測、急煞車和衝擊偵測.jpg?timestamp=1689918406.42007)